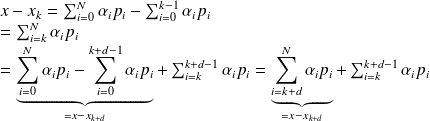The SPD case
The conjugate gradient method
The Ritz-Galerkin approach
The condition
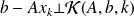 can be written
can be written
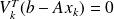 .
.
Using
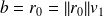 we have
we have
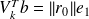 .
.
Because
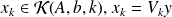 and
and
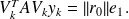
Note that
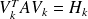 is a by product of the algorithm.
is a by product of the algorithm.If
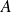 is symmetric,
is symmetric,
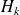 reduces to a tridiagonal
reduces to a tridiagonal
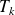 .
.
Fundamental : Proposition 3
Because
is SPD, the bilinear form
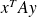 defines an inner product.
defines an inner product.
The Ritz-Galerkin condition
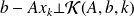 can be written
can be written
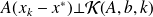 which also reads
which also reads
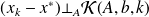 .
.
This latter condition implies that
 is minimal over
is minimal over
The Lanczos algorithm
In the Ritz-Galerkin approach the new residual
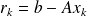 is orthogonal to
is orthogonal to
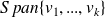 such that
such that
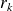 is colinear to
is colinear to
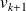 .
.
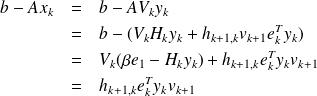
Since from
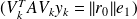
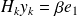 . We can relax the normalisation constraints on the
. We can relax the normalisation constraints on the
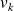 such that
such that
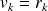 .
.
Because
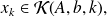 there exists a polynomial
there exists a polynomial
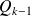 of degree
of degree
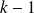 such that
such that
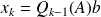
It follows that
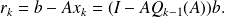 From the
From the
 column of
column of
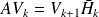 we have
we have
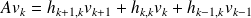
Using
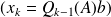 in both sides of
in both sides of

and identifying the coefficient for b we obtain
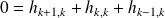 which defines the scaling
which defines the scaling
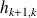 enabling to have
enabling to have
 Denoting
Denoting
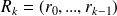 we have
we have
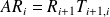 , where
, where
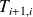 is a tridiagonal matrix with entries
is a tridiagonal matrix with entries
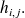
Similarly to the Arnoldi case we also have
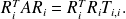
Because
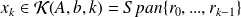 , we have
, we have
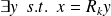 .
.
The Ritz-Galerkin condition writes
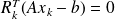 , and hence
, and hence

Using
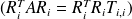 we obtain
we obtain
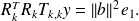
Because
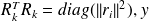 is the solution of
is the solution of
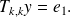
Note that for
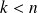 the construction of the orthogonal basis mustterminate ; in that case
the construction of the orthogonal basis mustterminate ; in that case
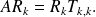
Let
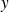 be the solution of
be the solution of
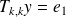 then
then
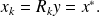 Indeed,
Indeed,
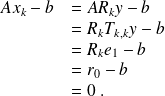
The main drawback of this approach is thet is requires to store
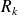 to build
to build
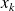 from
from
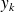 . Notice that so far we have only use the symmetry property of
. Notice that so far we have only use the symmetry property of
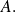 Exploiting the positivness of
leads to a clever variant of the above Lanczos algorithm that is better known as the Conjugate gradient method.
Exploiting the positivness of
leads to a clever variant of the above Lanczos algorithm that is better known as the Conjugate gradient method.
The CG Algorithm
|
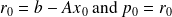
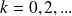
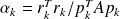
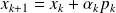
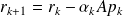
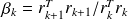
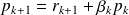
Some properties of CG
An upper-bound for the convergence rate
From
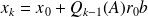 we have that
we have that
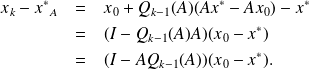
Then we have
 . In addition,
is minimal over
. In addition,
is minimal over
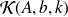 .
.
Fundamental : Proposition 4
The polynomial
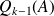 built by CG is such that
built by CG is such that
 ,
,
where
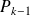 is the set of polynomial of degree
is the set of polynomial of degree
 .
.
Fundamental : Proposition 5
Let
be the
iterate generated by the CG algorithm then
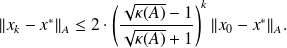
Proof
From Proposition (4) we have
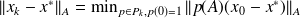 .
.
Let
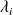 ,
,
 be the eigenvalues of
and
be the eigenvalues of
and
 where
where
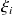 the components of
the components of
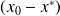 in this eigenbasis
in this eigenbasis
 .
.
We have
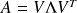 , and
, and
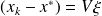 then
then
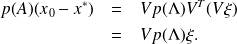
We therefore have that
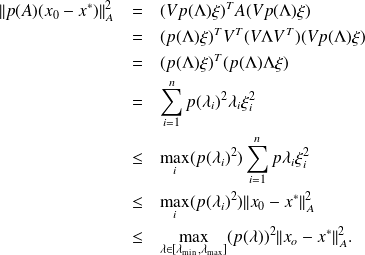
This shows that

Using an approximation theory result we have

where
 is the Chebyshev polynomial of the first kind of degree
is the Chebyshev polynomial of the first kind of degree
 . For
. For
 we have
we have
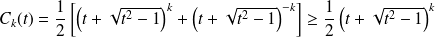
Let
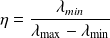 we have
we have
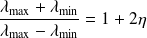
This implies that
 .
.
Plugging this bound in
and then in
completes the proof.
Convergence v.s. the spectrum of A
For symmetric matrices, the degree of the minimal polynomial
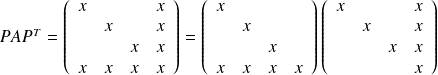
is equal to m the number of distinct eigenvalues.
Corollary 28
From Proposition(4) we have
 .
.
This indicates that CG will converge in at most $m$ iterations for any initial guess
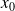 .
.
Coollary 29
If
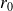 has
components in the eigenbasis, CG will converge in
iterations.
has
components in the eigenbasis, CG will converge in
iterations.
CG v.s. the A-norm of the error
Fundamental : Proposition 6
The CG iterates are such that
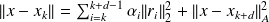 .
.
he A-norm of the error is decreasing, if
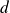 is such that
is such that
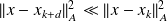
then
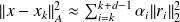 .
.
Proof
In the CG algorithm, the vectors
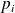 are conjugate wrt to
. Remember
are conjugate wrt to
. Remember
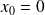 . Let
. Let
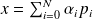 be the solution
be the solution
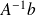 .
.
The result follows easily from the Pythagore Theorem with inner product
on the expression